Introduction
In recent years, machine learning (ML) has transitioned from experimental projects to essential components of business operations across industries. ML models are driving value at scale, revolutionising the way recommendation engines work, empowering fraud detection, and fine-tuning predictive maintenance and customer segmentation. However, building and maintaining these models is not always straightforward. One major challenge is managing the data features used to train, validate, and serve ML models.
Enter feature stores—a game-changing solution in the world of machine learning. Feature stores centralise and streamline the feature engineering process, allowing teams to develop robust models faster and more reliably. But what exactly is a feature store, and why should you care?
In this blog, we will explain feature stores, why they are so useful, and how they benefit organisations and data professionals alike.
Table of Contents
What Is a Feature Store?
A feature store is a centralised repository designed to store, manage, and serve machine learning features. Features are the input variables or attributes that ML models use to make predictions, such as a customer’s age, transaction history, or website activity.
Traditionally, data scientists and engineers create features manually using raw data, often storing them in separate files or databases. This approach can lead to duplication, inconsistency, and inefficiency. Feature stores solve these problems by offering a unified platform to:
- Ingest and transform raw data into features
- Store features in a reusable and scalable format
- Serve features to models in both training and real-time inference environments
Why Feature Stores Matter in Machine Learning Pipelines
Feature engineering is one of the machine learning lifecycle’s most time-consuming and error-prone steps. By offering a structured approach to feature management, feature stores unlock several benefits that make ML development faster, more scalable, and more reliable. Attending well-rounded Data Analytics Course will acquaint learners with these features from a practical perspective.
Improved Reusability and Collaboration
One of the biggest advantages of using a feature store is the reuse of features across projects. Data teams often reinvent the wheel, (Machine Learning) building the same features multiple times for different models or teams. A feature store eliminates this redundancy.
By creating a centralised catalogue of validated features, data scientists and analysts can easily find and reuse existing features, saving time and promoting consistency across projects. (Machine Learning) This kind of collaboration is particularly valuable for organisations with multiple ML teams or complex workflows.
Consistency Between Training and Inference
A common problem in ML deployment is the training-serving skew, where the features used to train a model differ slightly from those used in production. Even small inconsistencies can lead to poor model performance.
Feature stores help avoid this issue by standardising how features are generated and served. Whether you are training a model or serving it in a production environment, the features remain consistent, ensuring reliable results and reducing debugging time.
Real-Time Feature Serving
Many modern applications require real-time predictions—think fraud detection during a credit card transaction or personalised recommendations on a shopping website. (Machine Learning) For such use cases, real-time feature serving is critical.
Feature stores are built to support both batch and real-time data processing. Depending on the use case, they can serve precomputed features instantly or compute new ones on demand. This flexibility makes them ideal for both offline analytics and real-time decision-making.
Operational Efficiency
Managing features across various data pipelines can be complex and error-prone. Feature stores improve operational efficiency by offering monitoring, logging, versioning, and access control tools. (Machine Learning) This makes it easier to track feature usage, ensure data quality, and comply with governance standards.
Faster Time to Production
Because feature stores streamline the entire feature lifecycle—from creation to deployment—they significantly reduce the time it takes to move ML models from development to production. Teams can focus more on modelling and experimentation rather than on engineering and debugging data pipelines.
Who Should Use Feature Stores?
While feature stores are especially beneficial for organisations with mature machine learning practices, they can also be valuable for smaller teams aiming to scale their operations. Anyone involved in data science, ML engineering, or analytics can benefit:
- Data scientists can focus on modelling rather than repetitive data prep.
- Data engineers can build robust, reusable pipelines.
- ML engineers can deploy models faster and with fewer bugs.
- Business analysts gain confidence in the consistency and reliability of the data used in modelling.
Gaining exposure to tools like feature stores can be a major asset for those entering the data field. Enrolling in an inclusive data learning program can offer hands-on experience with modern data infrastructure, helping students build practical skills that employers highly value.
How Feature Stores Enhance Learning and Skill Development
The rise of feature stores reflects a broader trend in the data field—infrastructure maturity. As ML becomes more embedded in business workflows, professionals need to understand algorithms and the systems that support them.
It is imperative that aspiring analysts and data scientists understand these foundational systems. Courses often include topics like feature engineering, data pipelines, and ML lifecycle management—increasingly relevant concepts in today’s job market.
Popular Feature Store Tools
Several open-source and enterprise solutions are available for teams looking to adopt feature stores:
- Feast (Feature Store): One of the most popular open-source options, built for both offline and online feature serving.
- Tecton: An enterprise-grade feature store offering integration with modern cloud platforms.
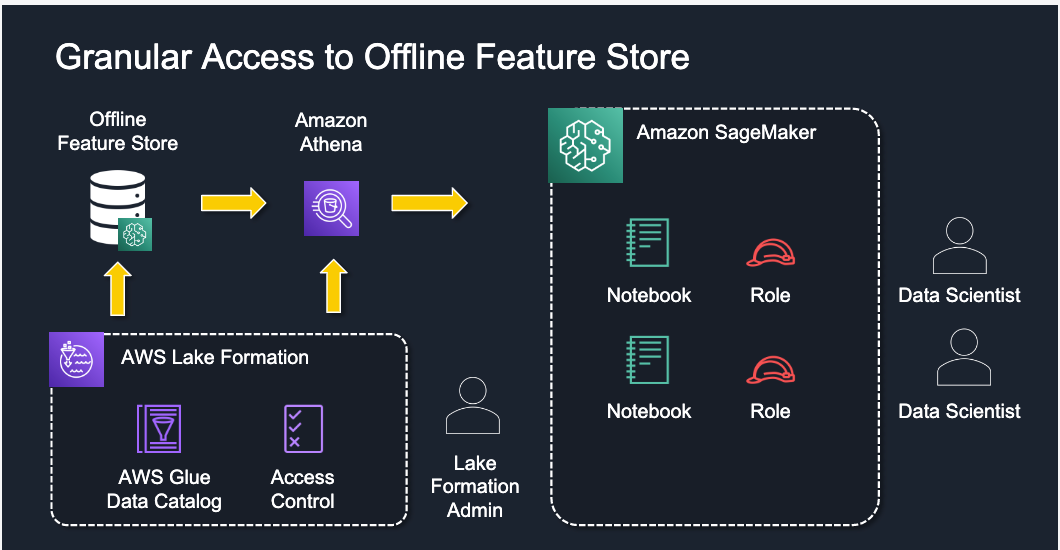
- AWS SageMaker Feature Store: Integrated with Amazon’s ML ecosystem.
- Databricks Feature Store: Works well within the Databricks environment and supports Delta Lake.
Each solution varies in terms of scalability, ease of use, and integration, so choosing one that aligns with your tech stack and business needs is important.
Conclusion: Feature Stores Are the Future of Scalable ML
As machine learning becomes central to business operations, the tools and practices surrounding it must evolve. Feature stores offer a practical, scalable solution to many challenges in building and deploying ML models.
By improving consistency, efficiency, and collaboration, feature stores enable teams to deliver high-quality models faster and more reliably. Whether you are a data engineer looking to streamline your pipelines or a student enrolled in a Data Analytics Course in Hyderabad, understanding feature stores is an investment in your future.
Incorporating this knowledge through structured learning, , can give you a competitive edge in a rapidly evolving industry. The future of ML is here—and it is organised, efficient, and feature-rich.
ExcelR – Data Science, Data Analytics and Business Analyst Course Training in Hyderabad
Address: Cyber Towers, PHASE-2, 5th Floor, Quadrant-2, HITEC City, Hyderabad, Telangana 500081
Phone: 096321 56744